Several months ago we've started an internal research project to find out how to enable our users to store and manage results from scans and all other manual tools in the Suite. The obvious solution was to do what everybody else was (and still is) doing, which is to come up with a proprietary file format and let our users deal with the pain of managing projects. However, we wouldn't call ourselves "innovative company" if this is how we were dealing with hard problems. We took the challenge very seriously and today we are ready to reveal a new member (albeit still in beta) of the online toolkit.
Why Project Files Suck
Before we dig into the solution we are proposing, there are several reasons why we believe that that project files are more or less useless and should be ignored whenever it is possible.
Reason #1
Project files usually contain a snapshot of data at the time when the data is collected. Imagine that you do a web application security scan today. Now you have a project file with the results. Later on you do another scan, which also contains results. Both files contain discreet information that is not correlated in any way. There could be a relationship between individual data items but you wouldn't know. This exercise of merging and sorting the data is left to the user. This is a huge waste of time and leads to no useful output but hours of misery.
Reason #2
To extract data you need to open the project inside the designated tool, i.e. project files are not directly search-able. You may be lucky in case you are dealing with a text-based file formats like JSON and XML but still you need to learn the grammar in order to do anything useful with the data. This vendor lock-in is unacceptable. Web application security is not just about reports but also about trends and finding answers to questions, which you won't be able to answer unless you can search for things that has happened in the past and are happening right now.
Reason #3
All tools rely on a manual process to export the data into project files. What this means is that you have to save your work before you exit. If you don't or if the application crashes, it is likely that you will loose all data and then you will have to start from scratch. Again, we find this to be an ill-thought process given that computers can perform the task of saving and updating data on their own quite easily.
Reason #4
As penetration testers and developers we just want to get our work done and worry about the details later. In other words, if you are in the middle of something and you want to do a quick test or perhaps a few checks here and there, the last thing you would want to do is to invest energy into setting up a project, or perhaps opening an old one, and remember to save afterwords. This is disruption of the thought process and only adds unnecessary stress. What will be better is to get done with the job and worry about the results later.
This What We Propose
So now when we know some of the problem we had to tackle. Working it all out on the back of our experience we manged to pull out a solution, which has it all. We had borrowed ideas from browsers and search engines and from all kinds of other places to make everything fit into one coherent system. Our aim was to be able to record various types of unstructured data and allow users to easily search it in various ways removing the need to organise, structure, save and essentially everything that gets in the way of the thought process.
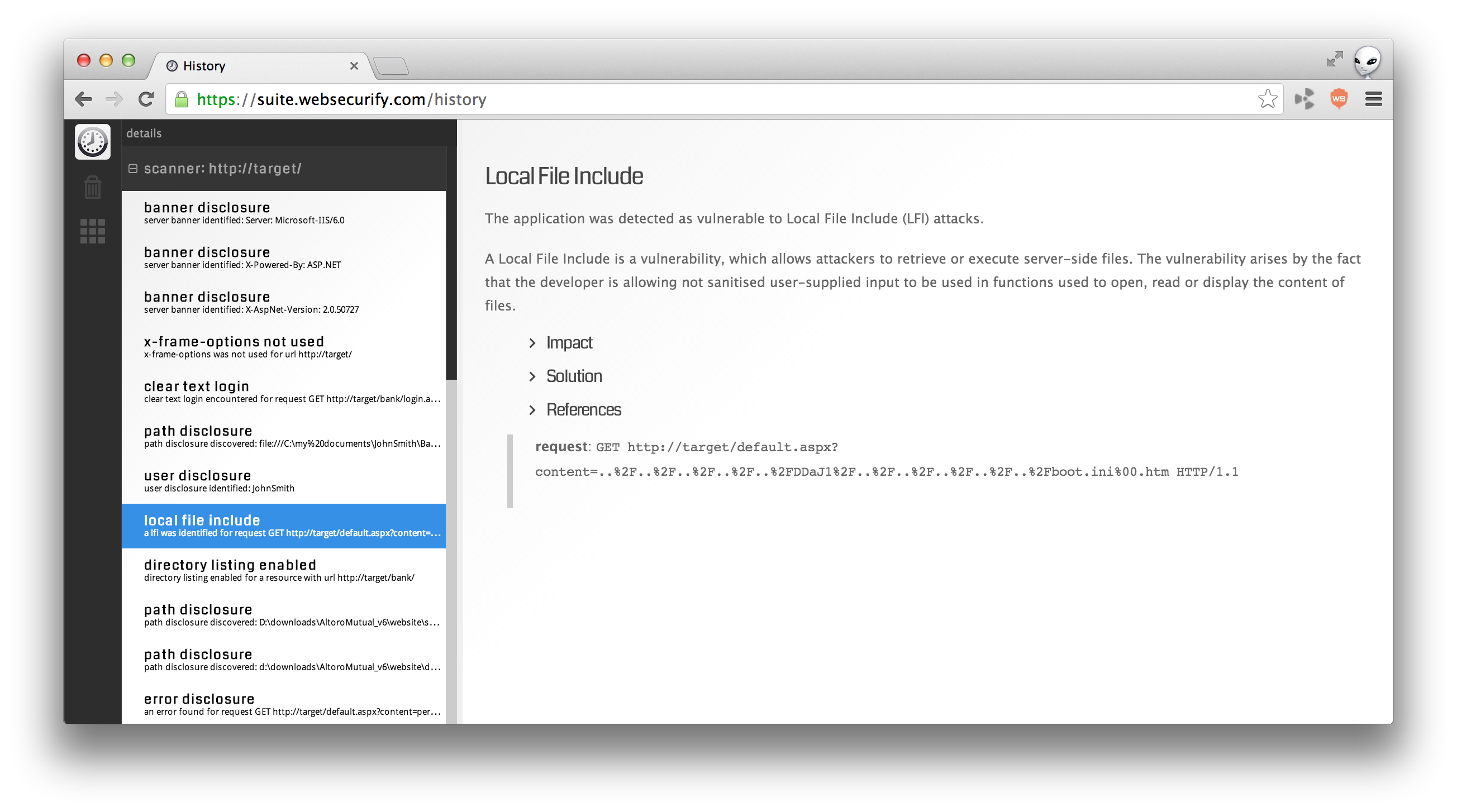
The tool is called History and in essence acts as a point of reference of all your actions - automatically saved and organised for your. You don't need to worry about the data because all of it is available whenever you need it. That is just the start because it does a lot more than this.
Feature #1
Data is no longer encapsulated into discreet project files but it is leaving flow of things. This way you can find relationship between various things and be able to track trends, answer to specific questions, reference back results from the past and much more. You can sort it by date, host and multiple other factors. We haven't ironed all things for this beta test but the mechanics are there to add all filters you will ever need to use your data the way you want it.
Feature #2
There is no vendor lock-in. Although we expose your history via a nice UI, underneath all of it you will find standard HTML5 technologies such as localStorage, WebSql and IndexDB. You can do with it whatever you want and there is plenty of help you can get outside of our expertise if you need to. Additionally, your data is well maintained and if you decide you can even back it up remotely with some of the available browser facilities.
Feature #3
Everything is saved automatically for you. You do not have to remember to "import", "export", "save" or "save as" anything. The History app doesn't have to be even open for the whole thing to work. Imagine you need to do manual inspection on some requests available in your app. You open the Resend tool and off you go. Once you are done just close the window. A month later you can still go back to all the things you did today without ever thinking about saving or exporting anything.
Feature #4
Everything is instantaneously available. Given that browsers are open all the time and the fact that our entire online toolkit runs on the back of Chrome and Firefox, you get access to your data at your wish without ever opening another tool. Everything is a click away and instantaneously available.
Future Development
We have mentioned on several places above that History is still an experimental tool very much in beta so it is likely that we will introduce breaking changes. At the time of writing only the activities from the Scanner are recorded but we will be adding the rest of the tools pretty soon. That being said, you are more than welcome to send us your feedback and suggestions how to make this tool even more useful to you.